MLOps Now — MLOps & LLMOps 2023 주요 트렌드
MLOps Now — MLOps & LLMOps
- 일시 — 2023년 11월 24일 오후 2시
- 장소 — 모두의연구소 강남캠퍼스
- 발표 내용 및 연사 —
- MLOps & LLMOps 2023 트렌드 - 안재만, Co-founder & CEO, VESSL AI
- 프로덕션 LLM을 위한 MLOps & AI 인프라 - 류인태, Product Manager, VESSL AI
- 고군분투 LLM 프로덕트 적용기 — Blind Prompting 부터 Agent까지 - Technical Lead & ML Engineer, LINER
- LLM 기반 추천 시스템 개발기 - 이태호, Technical Lead, Corca
MLOps & LLMOps 2023 트렌드 - 안재만, Co-founder & CEO, VESSL AI
1) LLMOps는? MLOps와의 차이는?
차이점 3가지
(1) Transfer learning -
(2) Compute management - 컴퓨팅의 효율적인 운영
(3) Feedback loops - LLM은 평가기준이 어렵다. 평가기준을 세우고 성능 향상을 만드는게 더 어려워짐
- 어떻게 변화 되었나?
- 새로운 컴포넌트가 생겨남
- 하부에는 컴퓨팅 효율적 운용을 위한 컴포넌트가 생겨남
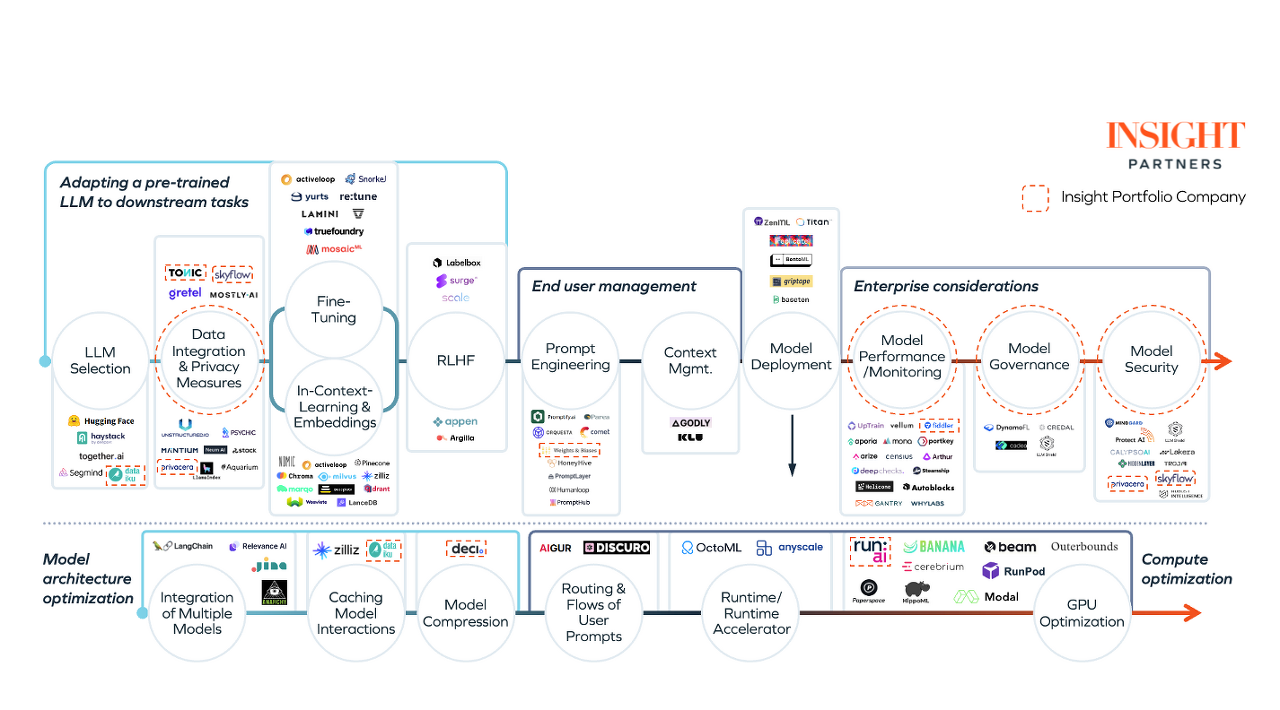
https://www.insightpartners.com/ideas/llmops-mlops-what-you-need-to-know/
Navigating the LLMops landscape: What you need to know
At Insight, we have been closely monitoring the rise of enterprise adoption of artificial intelligence (AI) for years – from the industry-specific applications of AI we first started tracking in 2017, the “MLops” infrastructure companies we discussed
www.insightpartners.com
- LLM Maturity model
- lv1 --> In context learning 프롬프트 엔지니어링
- lv2 --> RAG, 사내 파일 입력후 답변 생성
- lv3 --> Fine tuning
- lv4 --> Training
ex) Gernerative AI Personalization stack
(01)프롬프트 설정, 버전관리,
(02) RAG, 사내 문서를 벡터DB에 주입, LLM이 벡터 DB를 바탕으로 답변을 생성
(03) Fine tuninig --> 부작용이 많다. 원래 답변 수준을 망칠 가능성이 있다. RAG만으로 부족할때 시도해보는게 좋다
"LLM 학습부터 배포까지 하나의 단일한 인터페이스로 어떤 환경에서나 쉽게 노트북부터 파이프라인까지"
< Insights from MLOps world 2023.10.25~26 >
7 keywords
(1) LLMOps
(2) Finetuning LLMs
(3) Deploy LLMs
(4) LLM Evaluation
(5) Security/ Privacy
(6) RAG
(7) Business/ Enterprise
기업별 사례
01. Meta : Future of end to end ML Platform
- GPU의 Failure 발생했을때 어떻게 제외하고 모델을 안정적으로 학습시킬것인가?
- working well 할 수 있는 슈퍼컴퓨팅 자원(RSC) 연구를 한다, 딥러닝 모델이 잘 작동하는 칩을 설계한다.
- Acadia : 하드웨어적인 부분. 만장정도의 GPU를 사용했을때 어느정도 퍼포먼스가 나오는지
네트워크 트래픽, 이걸 어떻게 효율적으로 관리할 수 있는지 연구
02. Instacart : Supercharging ML/AI Foundations
- In-House ML Platform development --> 3년 정도 걸림
- vessl ai와 같은 솔루션으로 플랫폼을 제작하고 모델들을 하나씩 올려가고 있는중
프로덕션 LLM을 위한 MLOps & AI 인프라 - 류인태, Product Manager, VESSL AI
내용
바라보는 시장의 관점 , 어떻게 제품에 녹여내는가?
3 WHY
1) 왜 라마를 쓰는지
2) 왜 셀프 호스트 해야하는지
3) 제품레벨에서 deploy하려면 어떻게 해야 하는지
1) 오픈소스 모델
- 리더보드 --> lmsys leaderboard
- gpt4가 성능이 가장 좋음
- 오픈소스는 성능이 비교적 낮을 수 밖에 없다 --> 투자가 없기 때문
- openai fine tuning 비용 --> 4~12불 한번당
- 오픈소스로 파인튜닝하면 --> 인력고용, AWS비용 --> 80불 per fine-tuning
**특정 분야에 특화된 LLM모델 만들기에서 어느것이 나은가?
- LOL 챗봇을 만든다고 한다면?
- 아직 LOL 관련 질문에 제대로된 답을 못함, need more context 요청함
- 오픈소스 모델은 gpt4와 싸워 성능이 잘나오는게 아니라 파인튜닝 잘하는 모델로 개발되야 한다
- Open Source LLMs Direction 2 : Downstream Tasks
- 작은 모델이라도 다운스트림에서 , 특정 도메인에서 성능을 잘 낼수 있는 모델로 개발해야 하낟.
2)왜 셀프 호스트 해야 하는가
- 보안 -> over data
-Control --> 연구 방향이 과도기적 성향, SFT/RLHF/Multi-model/RAG 등 방향성이 너무 자주 바뀌어서
자신만의 모델이 있는게 대응해 나가기 쉽다
- Operation Stability - Open AI 서버가 터지면 대응이 어렵다
- Transparency - Open AI에서 어떻게 운용하는지 알수 없다--> 개선할 수 없다.
3) VESSLAI 에서는 어떻게 제품화하고 있나?
- 제품개발 철학 The atomic unit of MLOps --> 쪼갤수있는대로 쪼개서 구현하기
- 여러기능의 묶음 --> 파이프라인
- VESSL RUN
- Import : 다운로드 데이터
- Mount : Direct mount to run container
- Export : upload artifacts to storage -- 파라미터, 데이터 등
- resources --> spec, lmage, cluster
-yaml파일로 정리 -- 메타 데이터, 리소스, 볼륨, 런컨피그
RAG TEST 질문 --> what is Haerae? --> 해래는 한 논문에서 정의된 단어, 이걸 RAG로 적용해보고 질문해보고 알맞은 답변을 주는지 TEST 해봄
고군분투 LLM 프로덕트 적용기 — Blind Prompting 부터 Agent까지 - 허훈 Technical Lead & ML Engineer, LINER
허훈, 라이너,카카오브레인, NLP 개발자
liner workspace
1) Prompt Engineering
- 오픈에이아이에 프롬프트 가이드도 제공하고 있음
- LLM들은 대부분 프롬프트 엔지니어링 가이드는 비슷비슷함
- 프롬프트 수정으로 성능 개선이 이루어지고 있는게 맞나? 라는 생각을 하게됨
- --> 'Blind Prompting' 트라이얼, 에러에 대한 접근이다., 감으로 프롬프트 하는 거임
2) TEST CODE , 사전 정의된 질문을 가지고 프롬프트를 사용할때마다 테스트를 해보게 함
- 그러나 상황에 따라 다른 대답을 하는 LLM으로 인해 부정확한 방법이 됨
- 오픈에이아이에서 Seed Parameter를 내놓음.--> 하지만 most of time에 이라고 한정해서 완전한 방법은 아니었음
- 그러므로 매번 같은 결과가 나오지 않을 수 있다고 가정하고 테스트를 진행해야함
- 테스트 케이스가 많아지고, 시행횟수를 높일수록 일반화된 성능 경향을 발견 할 수 있음
3) RAG
- Liner는 추천시스템
- Annoy, FAISS, ScaNN, Milvus 다써보고 --> Elastic Search로 정착 --> term matching 서치
- 벡터서치만으로 답이 없다 , --> 텀매칭, 벡터서칭 을 모두 사용하는 하이브리드로 사용
- 펑션스코어 분포를 시각화해서 관리하는게 필요함 --> Grafana 사용
4) KEY Management
5) MODEL Management
- 11월8일에 open ai 러시아 Ddos 공격있었음, 사이트 정지됨
- Closed model 형태 필요성이 대두됨
- 여러 파운데이션 모델을 사용하는 안전 파이프라인을 구축하는게 필요해짐 (Fall back 로직)
6) 조언들
- open ai 에서 발표한 영상자료가 앱 개발에 도움될거임, 안드레아가 발표한거 USE GPT-4
- Reasoning 이 많이 필요한 문제라면 GPT4를 쓰는걸 추천
- Reasioning 이 많이 안필요하면 LLama2, Palm을 쓰는게 나음 *MT - Bench Score 참고 --> 공부하자!!
6-2) 블랭크 페이지 신드롬
- 꼭 대화형으로 개발할 필요는 없다.--> 대화형의 단점이 있다. 어떤걸 해야할지 첫페이지에서는 사용자는 모른다.
- Linus Lee 의 발표 영상 보기! 맥락과 의도의 중요성
- Intent , action, context를 기반으로 서비스는 구성됨을 인지하고 있다면 대화형 플랫폼에 귀속되지 않고 사고 할 수 있다.
- 예시) 대화형이 언제 필요한지? 효용을 느끼기 어렵다.
- 바로 효용을 제공할 수 있는 기능을 제공해야 한다. --> ASK AI ---> SUMMARY로 바꿈 --> 지표를 통해 UI 개선효과 확인
7) 시작할때부터 평가를 준비하자
- wandb에서 LLM관련 기능을 출시하고있음
- Prompt 넣었을때 스코어 어떻게 변화하는지 시각화
8) LLMOPs 플랫폼이 빠르게 성숙하는 중
- 실리콘밸리에서도 MLOPs 플랫폼 개발에 집중하고있다.
- pain point를 해소해주는 LLMOps 제품 많이 나오고 있다. --> vellum
어떻게 측정하는가 ? 성능을
Intent 케이스에 따라 평가해야함
GPT4로 테스트해보는게 낫지않나?
테스트 할때 안풀리는 문제의 원인을 어디로 판단해야할까?
- low level 부터 테스트해보고 해결이 되는지 확인 해보는게 좋다.
데이터의 폼이 다르다. PDF도 다 다르다 single컬럼, double 컬럼?
일반화된 로직을 짜는방법은 아직 어렵다.
일반화된 로직을 안짜면 레이턴시가 길다.
LLM 기반 추천 시스템 개발기 - 이태호, Technical Lead, Corca
광고 B2B SaaS solution
- 추천시스템 개발 업체
코르카 에이전트의 시작
코르카의 LLM
1) 18개월 동안 코르카가 바라본 LLM, PoC 해본것들
- LLM으로 무엇을 할까
2) 코르카의 LLM 개발
- 에이전트란? LLM을 활용하는 객체의 단위, 미션/행동/도구/외부지식
- EVAL -- coding, CORCA .ai 툴
- terminal, Code Editor 도구 개발을 통해 직접 코딩, 디버깅, 테스트, 배포 할 수 있도록 권한을 LLM에게 줌
- Langchain 활용
- 전세계 최초로 웹서비스를 개발하고 서빙하는 첫 에이전트였음
3) AI vilization
- Agent가 여러명일 필요성 --> 도구, 권한을 너무 많이 주면 , 사람처럼 힘들어함,, 역할분담을 나눠서 하는게 낫다
- 도구를 쥐어주지 말고 직접 사용하면서 개선한다면?
- AGI의 궁극적인 형태이며 지능이 하나가 아니라 지능의 집단이자 문명
- 같은 GPT인데 ?의미가 있어? --> 대화를 하면서 학습이 된다면?, 학습이 될까?
4) 코르카의 제품화된 LLM
- LLM으로 성공할 프로덕트는? --> 파도를 거스르지말고 파도위에 올라타라
- open ai, google, meta를 따라가라
- Do Things that don't scale.
- 어떻게?
- Agent를 새로운 공간으로 옮기자 ! --> ADCIO Agent
- Coplilot이 잘 된 이유는 성능보다 쓰기 쉬워서이고 쓰기 쉬운 이유는 코딩창 안에 있기 떄문이다.
- Agent간의 협력구조를 만들자 --> Agent Village
- 확장가능한 Agent를 확대하자
- ADCIO Agent
- 검색이 잘되는 이커머스 플랫폼은 많지 않다.
- 대화를 토대로 사용자의 니즈를 분석하여 상품을 추천해준다면?
- 대화 지면을 광고에 사용한다면? --> 대화창에 광고 경매를 매긴다면?
- 대화를 통해 유저의 의도를 얼마나 정확하게 이해하고 얼마나 정확하게 수행할 수 있는가?
- Keyword Search ( Elastic Search)
- Vector Search ( Weaviate, Pinecone,..)
- Text to SQL
- 에이전트를 매장의 점원으로 만들자!
- 웹브라우징에서 개인화된 광고, 상품을 보여주게 하는 컨셉.
남자가 검색했는데 여자 용품 나오는건 불필요한 광고, 상품을 보여주는 거임
오픈소스 모델 성능을 gpt보다 높이는 방법
-Real time reverse fine tuning
- 대화 프롬프트를 바탕으로 바로 학습을 진행 --> 따로 pre프롬프트 넣거나 할 필요가 없음
- In-context learning을 대체하자.
- context를 실시간으로 parameter에 반영해버리자
Advantage 1. 추론비용 대폭감소 2. Text-based RLHF 를 통해 Agent 진화 3. 에이전트 간의 대화를 토대로 실시간 학습가능 --> Multi-Agent 협업시 job이 생김
Q) Adversarial attack 은 어떻게 하나요?Q) 몇턴 정도의 대화를 통해 파악할 수 있나? - 너가 원한게 이게 맞아? 라는 질문을 하도록 하고 확인하는 방식으로 진행
-오픈소스 모델로 제품화하는 곳은 그렇게 많지 않다...
A100 8장으로 사용 중