GPU H100 - Transformer Engine - 02.적용하는법/ Docs review(Getting Started)
Getting Started
Overview
Transformer Engine (TE)을 사용하는 이유
- FP8 지원 → 더 낮은 메모리 사용량
- Transformer 아키텍처 지원
- 정밀도(Precision)를 유지하는 솔루션을 자동으로 적용되도록 구현
- 기존 DL 프레임워크와의 호환성
- 독립적인 C++ API도 지원함
Let's build a Transformer Layer!
우리는 일반 PyTorch 모듈을 사용하여 기본 트랜스포머 계층을 구축한다. 이는 추후 트랜스포머 엔진과의 비교를 위한 기준이 될 것입니다.
먼저 일반 PyTorch를 사용하여 GPT 인코더 계층을 생성합니다. 그림 1은 전체적인 구조를 보여준다.
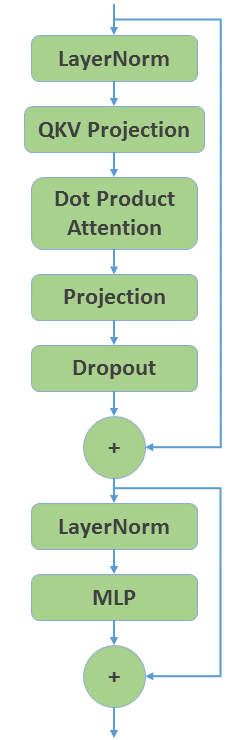
모델 구성 요소별 사용한 Pytorch 라이브러리:
- LayerNorm : torch.nn.LayerNorm
- QKV Projection : torch.nn.Linear *
- DotProductAttention : DotProductAttention from quickstart_utils.py
- Projection : torch.nn.Linear
- Dropout : torch.nn.Dropout
- MLP : BasicMLP from quickstart_utils.py
* 실제로 Q,K,V 3개의 Linear layer를 사용해야 한다. 하지만 여기선 1개의 Linear Layer를 사용하고 노드수를 3배로 늘여서사용한다.
quickstart_utils.py 에 정의된 함수를 사용해서 코드를 작성함.
import torch
import quickstart_utils as utils
class BasicTransformerLayer(torch.nn.Module):
def __init__(
self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1,
):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln1 = torch.nn.LayerNorm(hidden_size, eps=layernorm_eps)
self.qkv_projection = torch.nn.Linear(hidden_size, 3 * hidden_size, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = torch.nn.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln2 = torch.nn.LayerNorm(hidden_size, eps=layernorm_eps)
self.mlp = utils.BasicMLP(
hidden_size=hidden_size,
ffn_hidden_size=ffn_hidden_size,
)
def forward(
self,
x: torch.Tensor,
attention_mask: torch.Tensor
) -> torch.Tensor:
res = x
x = self.ln1(x)
# Fused QKV projection
qkv = self.qkv_projection(x)
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln2(x)
x = self.mlp(x)
return x + res모델은 정의했고 이제 실제로 실행해보자
# Layer configuration
hidden_size = 4096
sequence_length = 2048
batch_size = 4
ffn_hidden_size = 16384
num_attention_heads = 32
dtype = torch.float16
# Synthetic data
x = torch.rand(sequence_length, batch_size, hidden_size).cuda().to(dtype=dtype)
dy = torch.rand(sequence_length, batch_size, hidden_size).cuda().to(dtype=dtype)basic_transformer = BasicTransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
)
basic_transformer.to(dtype=dtype).cuda() [3] BasicTransformerLayer(
(ln1): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(qkv_projection): Linear(in_features=4096, out_features=12288, bias=True)
(attention): DotProductAttention(
(dropout): Dropout(p=0.1, inplace=False)
)
(projection): Linear(in_features=4096, out_features=4096, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(ln2): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(mlp): BasicMLP(
(linear1): Linear(in_features=4096, out_features=16384, bias=True)
(linear2): Linear(in_features=16384, out_features=4096, bias=True)
)
)torch.manual_seed(1234)
y = basic_transformer(x, attention_mask=None)
utils.speedometer(
basic_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)Mean time: 43.0663916015625 ms
Transformer Engine 경험하기
** Meet 경험하다
<Summary>
간단한 TE 모듈인 Linear, LayerNorm 모듈을 적용해보자
torch.nn.Linear → TE 모듈로 바꾸기
torch.nn.LayerNorm → TE 모듈로 바꾸기
import transformer_engine.pytorch as te
class BasicTEMLP(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int) -> None:
super().__init__()
self.linear1 = te.Linear(hidden_size, ffn_hidden_size, bias=True)
self.linear2 = te.Linear(ffn_hidden_size, hidden_size, bias=True)
def forward(self, x):
x = self.linear1(x)
x = torch.nn.functional.gelu(x, approximate='tanh')
x = self.linear2(x)
return x
class BasicTETransformerLayer(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln1 = te.LayerNorm(hidden_size, eps=layernorm_eps)
self.qkv_projection = te.Linear(hidden_size, 3 * hidden_size, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = te.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln2 = te.LayerNorm(hidden_size, eps=layernorm_eps)
self.mlp = BasicTEMLP(
hidden_size=hidden_size,
ffn_hidden_size=ffn_hidden_size,
)
def forward(self,
x: torch.Tensor,
attention_mask: torch.Tensor):
res = x
x = self.ln1(x)
# Fused QKV projection
qkv = self.qkv_projection(x)
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln2(x)
x = self.mlp(x)
return x + res
basic_te_transformer = BasicTETransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
)
basic_te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_basic_te_model(basic_te_transformer, basic_transformer)
torch.manual_seed(1234)
y = basic_te_transformer(x, attention_mask=None)
utils.speedometer(
basic_te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)Mean time: 43.1413232421875 ms
여러개 TE모듈을 활용하기(Fused* TE Modules)
**Fused 여러 개의 작은 모듈이 하나로 합쳐져서 하나의 큰 모듈로 구성되는 것을 의미
TE모듈은 커스텀한 모델에도 적용이 가능하다. (Layer형태로 모듈식으로 사용하면 되니까) 게다가 여러 모듈을 최적화해서 사용하는 방법도 있다. 그걸 알아보자.
TE에서sms 여러 개의 Layer를 포함하는 더 큰 단위의 모듈을 제공합니다.
**Coarser modules 거친, 더 넓은 범위의, 더 큰단위의란 의미로 쓰임
**modules that Span multiple layers 여러개의 모듈이 하나의 공간에 존재한다는 의미
- LayerNormLinear
- LayerNormMLP
- TransformerLayer
아래 코드에서는 LayerNormLinear, LayerNormMLP를 적용한 코드이다.
class FusedTETransformerLayer(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln_qkv = te.LayerNormLinear(hidden_size, 3 * hidden_size, eps=layernorm_eps, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = te.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln_mlp = te.LayerNormMLP(hidden_size, ffn_hidden_size, eps=layernorm_eps, bias=True)
def forward(self,
x: torch.Tensor,
attention_mask: torch.Tensor):
res = x
qkv = self.ln_qkv(x)
# Split qkv into query, key and value
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln_mlp(x)
return x + resfused_te_transformer = FusedTETransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
fused_te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_fused_te_model(fused_te_transformer, basic_transformer)
torch.manual_seed(1234)
y = fused_te_transformer(x, attention_mask=None)
utils.speedometer(
fused_te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)Mean time: 43.1981201171875 ms** eps 엡실론, 아주작은값, 분모값에 더해주면서 발산을 예방하는 목적으로 사용
이 모든 아키텍처를 하나의 모델로 만든 함수도 지원한다. 가장 효율적으로 작동되도록 만든 Transformer 모델 함수이다.
- TransformerLayer
import transformer_engine.pytorch as te
te_transformer = te.TransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_transformerlayer_te_model(te_transformer, basic_transformer)
torch.manual_seed(1234)
y = te_transformer(x, attention_mask=None)
utils.speedometer(
te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)Mean time: 39.99169921875 ms
FP8의 활성화
위에서는 TE 모듈로 모델 아키텍처를 만들었지만 이걸 실행한다고 FP8로 학습이 실행되는 것은 아닙니다.
FP8 Datatype을 적용해서 학습을 진행시키려면, 코드를 추가해줘야 합니다.
fp8_autocast 라는 텍스트로 forward pass 부분을 감싸주면됩니다. 주의할점은 backward pass는 감싸주면 안됩니다.
Delayed Scaling 방식*을 먼저 정의해주고, with문에 te.fp8_autocast의 인자값으로 넣어주면 됩니다.
**Delayed Scaling을 이해하려면 'GPU H100 Transformer engine 작동원리' 이란 글을 참조하세요
from transformer_engine.common.recipe import Format, DelayedScaling
te_transformer = te.TransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_transformerlayer_te_model(te_transformer, basic_transformer)
fp8_format = Format.HYBRID
fp8_recipe = DelayedScaling(fp8_format=fp8_format, amax_history_len=16, amax_compute_algo="max")
torch.manual_seed(1234)
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
y = te_transformer(x, attention_mask=None)
utils.speedometer(
te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
fp8_autocast_kwargs = { "enabled": True, "fp8_recipe": fp8_recipe },
)Mean time: 28.61394775390625 ms